
In 3 previous blog posts I compared various azure storage technologies with regards to performance and scalability in typical web usage scenarios. I was actually done with the series, but with all that interesting data, I decided to throw my current favorite search/storage/no-sql technology into the mix to get an idea about how it all compares. So - ElasticSearch enters the competition!
Those who knows me, will know I have a long standing passion for Search technology coming from my many years at Mondosoft back in the dotcom era when we were delivering Mondosearch - one of the best site-search engines around at the time. When I much later got introduced to ElasticSearch through Truffler (that later came to be known in the shape of Episerver Find) I was instantly hooked! Beautiful API (Truffler/Find), but also backed by some extremely capable and powerful technology. I remember, at one point - early on with Episerver Find, I had gotten my hands on some real life data - and lots of it (around 200 million rows) I needed to learn and extract knowledge from real-time lookups in the data so I pushed it into an Elastic Index. Sure, on the old hardware we had it took a few days to get all the data in there, but then I could do complex queries in fractions of a second - and it was beautiful! No more SQL, rather structured documents that corresponded exactly to the objects I persisted and LINQ like syntax to query with! Everything was indexed and extracting aggregations/facets was almost as fast as regular queries.
Later, I also started using ElasticSearch for pet-projects outside of Episerver - and I got used to the NEST API. It's not as neat and easy to learn as Episerver Finds API, but very powerful once you get the hang of it. And of course - the engine underneath that powers it all makes it worth it.
Often, I find myself wanting to store data on websites directly in ElasticSearch just because it's so easy and comfortable. I was recently helping out a travel agent with combining flights and hotel availability for an online map (but that's really a story for another time) but even with a hundred millions combinations changing constantly it was still fast to navigate, group and extract data from!
So - I figured it would be a worthy opponent to our former contestants.
The setup
Now, while it's very easy to setup and run ElasticSearch anywhere - and there are tons of blog posts doing it on Azure, (like this one), it still requires containers or VMs to run and those cost money. And since my free allowance has expired and I'm too cheap to pay more for the course of this blog post, I decided to use my already existing virtual server that I'm using for many of my projects - including this blog for the purpose. Sure, ideally Elastic should be set up on multiple servers as it scales out very powerfully, but I figured for a mere 1 million records this server should be sufficient.
My server, by the way is a 16 Gb 6 vCore, 600 Gb SSD virtual server hosted by Host-Europe in Germany at the amazing cost of 39.99 EUR a month running Windows. I'll probably do a blog post later on how I've got my entire setup going for next to nothing. But again I digress.
I've used a standard installation of ElasticSearch on it and made it accessible through a reverse proxy on my IIS with SSL as well.
To run the tests, I've basically used my laptop from my home in Denmark so there should be some network latency in the numbers as well.
First, I simply did the standard CRUD test:

(Note that I've skipped the Blob Storage from this round)
So, these numbers are ms per operation when performed sequentially. ElasticSearch is decent (although still beaten by Cosmos). Updating is slow as it does 2 full roundtrip. Also - keep in mind when comparing these numbers that ElasticSearch is on a completely different server-setup with significant network latency, where as the other numbers are made by a server on the same gigabit network as them. Still it managed to beat the S0 SQLAzure on read speed!
Now, the real power of Elastic is in it's ability to scale. So - for the next set of tests I started firing at it with 20 sequential threads. I also tried a set of calls where I took advantage of the Bulk calls in Elastic (typically with 100 documents at a time).
To even out the playing field for this match, I picked the S3 SQL Azure and Cosmos. First the indexing:
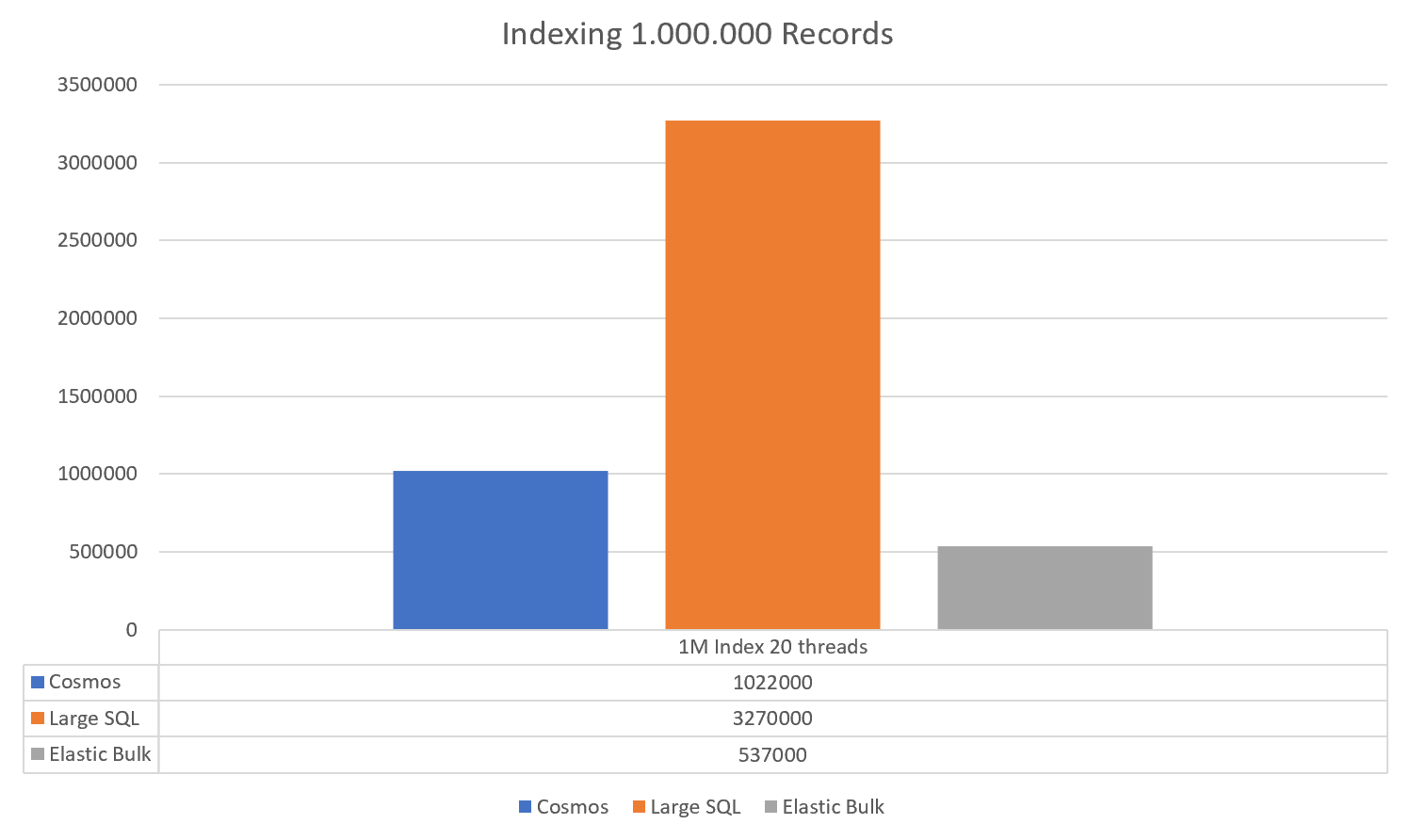
The vertical axis is the total time in MS to index 1 million records (rounded off).
So, Cosmos spent 1022 seconds, a large SQL instance spent 3270 seconds and ElasticSearch called with Bulk calls spent 537 seconds! I didn't include it in the graph, but ElasticSearch called with individual calls (but still 20 threads) 3082 seconds - so comparable to the large SQL instance. NO-SQL fully indexed databases like Elastic is supposedly slow at indexing. But this is definitely acceptable.

If we look at the Read/Update/Delete measurements with 20 sequential threads, we once again see the Elastic Bulk as a strong contestant. But the real power of course is shown when we do something crazy like looking up records on an a field we didn't plan to use when we defined our indexes. Here 100 reads took 3.6 seconds for Cosmos, 334.9 seconds for struggling S3 SQL Azure, but only 1.1 seconds for our Elastic Bulk! Non-bulk calls to ElasticSearch did it in 3.6 seconds - so very comparable to Cosmos in that sense. The reason is of course that Elastic maintains indexes on pretty much everything - and I suspect so does Cosmos.
The updated spreadsheet looks like this:
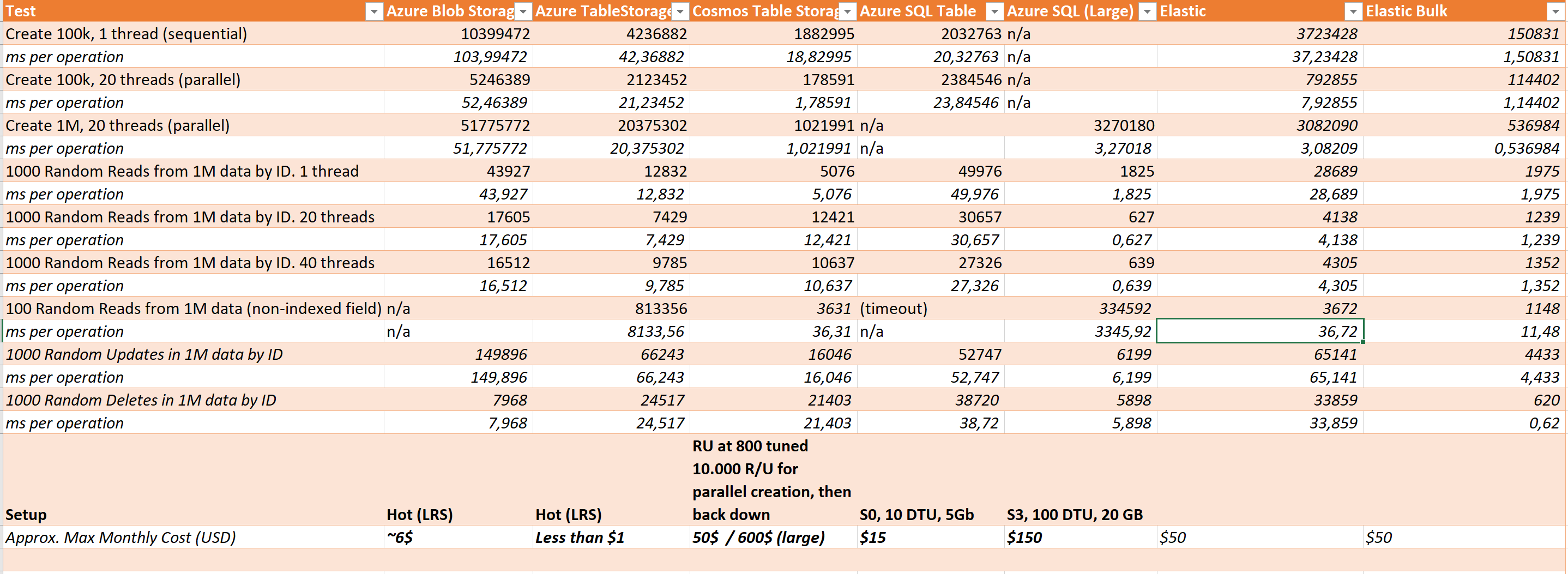
Now, before you all start yelling at me for comparing apples and oranges; Yes, I am aware that it's not fair to compare these technologies exactly like this. My comparison is more of a practical nature as a guy who enjoys storing lots of data and using it in various web applications - sometimes presenting it in new and different views. And at the same time I have a limited budget. The right tool for the job is a decision that should be based on many different factors - price, performance and scalability are just some. Durability, flexibility and ease of use for developers are other factors I haven't dived into in these blog posts.
Also - for the Elastic Bulk measurements it's worth noting that both Cosmos, Table Storage and SQL have ways you can call them in bulk as well. And you would very likely see significant performance increases there as well.
It could certainly also be interesting to look at when the data gets even bigger - why only 1 million rows? It could just have easily have been 1.000.000.000 and we would really start to see where the scalability kicks in. But I'll leave that for a future post.
As a last thing, here is a little quiz: Which of the tested technologies do you think required the most lines of code (in total) to use for both creating, reading (by id), querying (non-id), updating and deleting? Keep in mind my crappy coding standards and leave your guess in the comments below. Thanks for reading.